Breathing new life into a 200 year-old document
Feb 15, 2018 • Jed Lehmann

An interesting challenge came our way, and of course, we love interesting challenges!
We had a client who has been managing a long form document for over 200 years! The content of the document was difficult to manage due to its complexity & length (approx. 300 pages). It was difficult to edit because it was in XML and Word format. And the worst part was they had to edit both of these file formats each time they made a change to the document. This increased the risk of error and the time spent managing the document.
The document goes through periodic editing and subsequent publishing to various channels.
The publishing channels
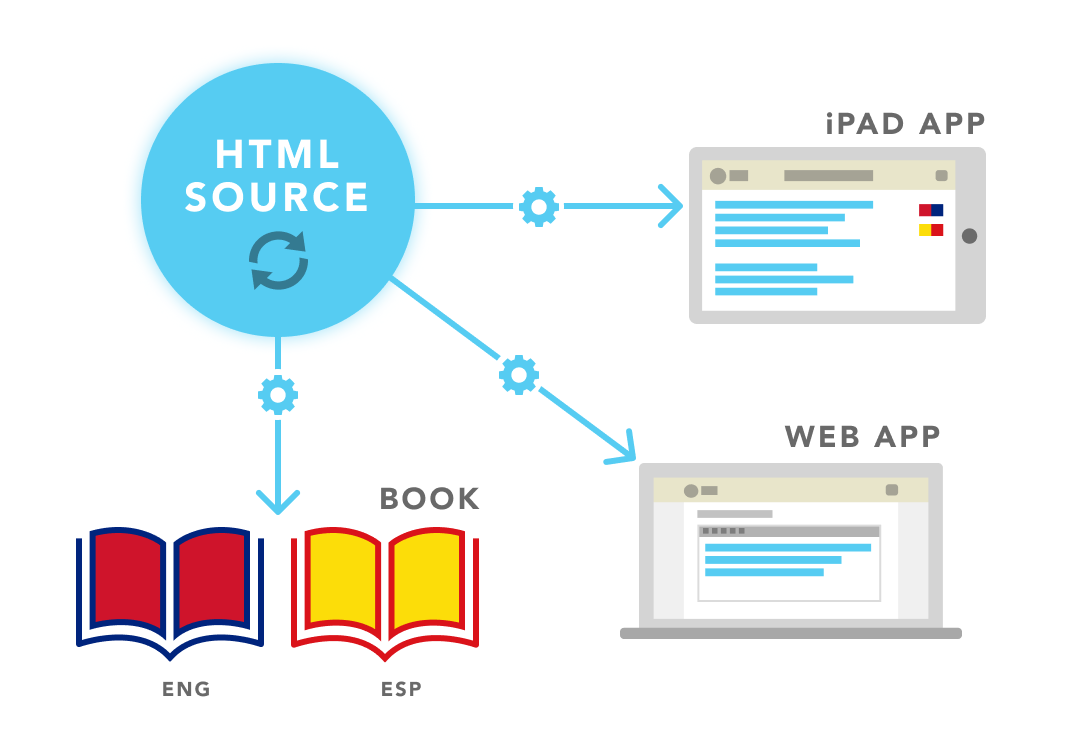
- A printed book with real book formatting, in English and Spanish.
- A Ruby on Rails web app for managing edits to individual paragraphs.
- An iPad app with linked table of contents and separated chapters.
The source of truth
Our goals for the document were as follows:
- be easy to view and edit
- be future proof (i.e. still be readable and editable in a few decades)
- preserve semantics (to maintain structuring of document)
- support multi-channel publishing from a single source
The first question we asked ourselves – what is a good format for a long-form document that has multiple uses and can serve as a single source of truth?
After considering various formats, and other avenues such as building a custom software tool or using a headless CMS app to manage the content, HTML was the clear winner of the existing formats, and any other formats we uncovered.
Here's how HTML stacks up against the existing formats:
| Word | XML | HTML | |
|---|---|---|---|
| Readability | Yes | ✕ | Yes |
| Ease of editing | Yes | ✕ | Yes |
| Future proof | ✕ | Yes | Yes |
| Semantic markup | ✕ | Yes | Yes |
| Multichannel | ✕ | Yes | Yes |
HTML is the language of the web, and is extremely versatile. It can be converted to book format with fantastic typography, can be semantically marked up so the content is readable by machines and people, and can be output to any channel we could think to name.
The client was comfortable with the idea of editing the document as HTML, so we got to work converting the original XML source file to HTML.
The conversion to HTML
To ensure accuracy, we wrote a tool to automate the conversion from XML to HTML. This gave us control over exactly how we wanted the HTML tags to be output for easy management and publishing to the various channels.
The book format
The requirement is to have a print-ready PDF with all the trimmings: headers, opposing page layout, table of contents, full index listing and fine-tuned typography.
We looked to Prince to provide us with page formatting using CSS for styling.
Setting up the printed page size, numbering and other basic page layout features were a breeze. And text formatting uses plain old CSS, so that was a no-brainer.
However, the existing book layout had a few tricky challenges we had to reproduce:
Generated content in headers
The document has generated content in headers, using elements such as section titles. The content to be generated varies from chapter to chapter, so we targeted each chapter individually using @page rules, and used content strings to output the content into the header area of the page.
Marginalia
Definitely the biggest layout challenge of the project, the printed book has margins on the outside of the page (which alternate depending on left/right page). Each marginalia text relates to a specific word in the main content, and must be aligned horizontally to it. The marginalia is embedded in the HTML, sometimes inside several levels of ordered lists.
Traditional CSS layout as used in Prince didn't surface any solutions to create the layout we wanted. Upcoming CSS layout methods would have been the answer here, however the features we could have used are not available in Prince (at the time of writing).
So we ended up editing our PDF generation script so it does a double pass: one version of the document with left margins, and one with margins on the right. The script then merges the two versions to create one print-ready PDF with alternating margins.
Sweating the details
The document has many small details such as leading dots in the index, custom numbering for nested lists. These details had to be converted exactly as they appear in the source document, which added complexity to the conversion tool.
The iPad app
The document will be shown in an iPad app at a conference with thousands of visitors all viewing it on the local network. It needs to be easily navigable, so we wrote a script to separate the source HTML file into individual chapters, with a linked table of contents for easy navigation. This script can be run at any time from the source document to ensure updating the iPad app is easy, fast and accurate.
Translation to Spanish
The document is translated to Spanish once editing is completed for each triennium. This is done by supplying the HTML to a translation house who can use the source file for translation. Their system can detect changes, so each time they receive a new version, they only need to update the translations for new or changed content. The translated version comes back to us as HTML, ready for pushing out to the various channels.
Exported for use in the client's Rails application
Another channel for the document is the client's Ruby on Rails application. A requirement is to have each paragraph available in the application for editing, with facility for suggesting changes to the master document which then get integrated back into the source HTML. We have written a script which splits every paragraph in the document into separate entities and imports it into the Rails application.
A flexible, future-friendly format
Using HTML for this document gives us full confidence we can output to any channel that gets requested by the client.